 History
History
For those of you who have genuinely been following NetApp as a storage company over the years, you may already know that NetApp, contrary to the popular belief as a storage company, has always been a software company at their core. Unlike most of their competitors back in the day such as EMC or even HPe, who were focused primarily on raw hardware capabilities and purpose built storage offerings specific for each use case, NetApp always had a single storage solution (FAS platform) with fit for purpose hardware. However their real strength was in the piece of software they developed on top (Data OnTAP) which offered so many different data services that often would require 2 or 3 different solutions altogether to achieve when it comes to their competition. That software driven innovation kept them punching well beyond their weight to be in the same league as their much bigger competitors.
Over the last few years however, NetApp did expand out their storage offerings to include some additional purpose built storage solutions out of necessity to address many niche customer use cases. They built the E series for raw performance use cases with minimal data services, EF for extreme all flash performance and acquired SolidFire offering which was also a very software driven, scalable storage solution built on commodity HW. The key for most of these storage solution offerings was still the software defined storage & software defined data management capabilities of each platform and the integration of all them through the software technologies such as SnapMirror and SnapVault to move data seamlessly in between these various platform.
In an increasingly software defined world (Public & Private cloud all powered primarily through software), the model of leading with software defined data storage and data management services enables many additional possibilities to expand things out beyond just these Data Center solutions for NetApp, as it turned out.
NetApp Data Fabric

NetApp Data Fabric was an extension of that OnTAP & various other software centric storage capabilities beyond the customer data centers in to other compute platforms such as Public clouds and 3rd party CoLo facilities that NetApp set their vision a while ago.
The idea was that customers can seamlessly move data across all these infrastructure platforms as and when needed without having to modify (think “convert”) the data. NetApp’s Data Fabric at its core, aims to address the data mobility problem caused by platform locking of data, by providing a common layer of core NetApp technologies to host data across all those tiers in a similar manner. In addition, it also aims to provide common set of tools that can be used to manage those data, on any platform, during their lifetime, from the initial creation of data at the Edge location, to processing the data at the Core (DC) and / or on various cloud platforms to then long term storage & archival storage on the core and / or Public cloud platforms. In a way, this provide customers the choice of platform neutrality when it comes to their data which, lets admit it, that is the life blood of most digital (that means all) businesses of today.
New NetApp Data Fabric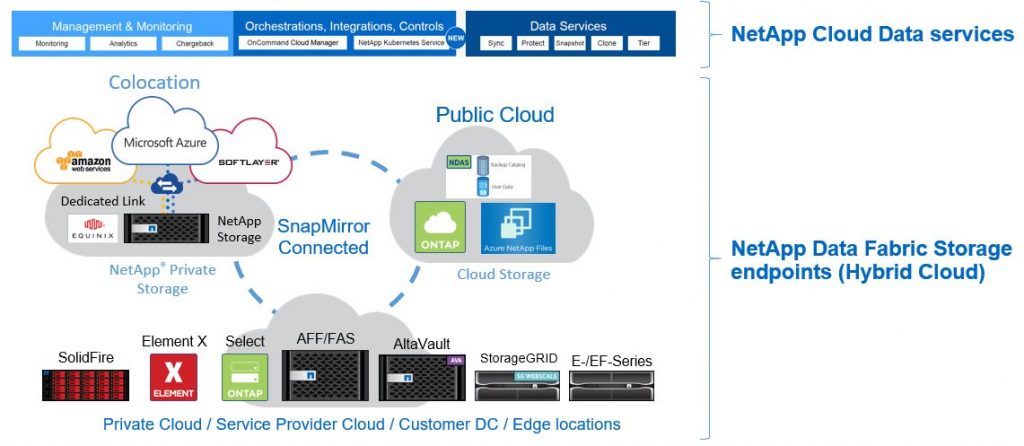

Insight 2018 showcased how NetApp managed to extend the initial scope of their Data Fabric vision beyond Hybrid Cloud to new platforms such as Edge locations too, connecting customer’s data across Edge to Core (DC) to Cloud platforms providing data portability. In addition, NetApp also launched a number of new data services to help manage and monitor these data, as they move from one pillar to another across the data fabric. NetApp CEO George Kurian described this new Data Fabric as a way of “Simplifying and integrating orchestration of data services across the Hybrid Cloud providing data visibility, protection and control amongst other features”. In a way, its very similar to VMware’s “Any App, Any device, Any cloud” vision, but in the case of NetApp, the focus is all about the data & data services.
The new NetApp Data Fabric consist of the following key data storage components at each of its pillars.
- Private data center
- NetApp FAS / SolidFire / E / EF / StorageGRID series storage platforms & AltaVault backup appliance. Most of these components now directly integrates with public cloud platforms.
-
Public Cloud
-
NetApp Cloud Volumes – SaaS solution that provides file services (NFS & SMB) on the cloud using a NetApp FAS xxxx SAN/NAS array running Data OnTAP that is tightly integrated to the native cloud platform.
- Azure NetApp files – PaaS solution running on physical NetApp FAS storage solutions on Azure DCs. Directly integrated in to Azure Resource Manager for native storage provisioning and management.
- Cloud volumes ONTAP – NetApp OnTAP virtual appliance that runs the same ONTAP code on the cloud. Can be used for production workloads, DR, File shares and DB storage, same as on-premises. Includes Cloud tiering and Trident container support as well as SnapLock for encryption.
-
- Co-Lo (Adjacent to public clouds)NetApp private storage – Dedicated, Physical NetApp FAS (ONTAP) or a FlexArray storage solution owned by the customer, that is physical adjacent to major cloud platform infrastructures. The storage unit is hosted in an Equinix data center with direct, low latency 10GBe link to Azure, AWS and GCP cloud back ends. Workloads such as VMs and applications deployed in the native cloud platform can consume data directly over this low latency link.
- Edge locationsNetApp HCI – Recently repositioned as a “Hybrid Cloud Infrastructure” rather than a “Hyper-Converged Infrastructure”, this solution provides a native NetApp compute + Storage solution that is tightly integrated with some of the key data services & Monitoring and management solutions from the Data Fabric (described below).
Data Fabric + NetApp Cloud Services
While the core storage infrastructure components of Data Fabric enables data mobility without the need to transform data across each hop, customers still need the tools to be able to provision, manage, monitor these data on each pillar of the data fabric. Furthermore, customers would also need to use these tools to manage the data across non NetApp platforms that are also linked to the Data Fabric storage pillars described above (such as native cloud platforms).
Insight 2018 (US) revealed the launch of some of these brand new data services & Tool from NetApp most of which are actually SaaS solutions hosted and managed by NetApp themselves on a cloud platform. While some of these services are fully live and GA, not all of these Cloud services are live just yet, but customers can trial them all free today.

Given below is a full list of the announced NetApp Cloud services that fall in to 2 categories. By design, these are tightly integrated with all the data storage pillars of the NetApp Data Fabric as well as other 3rd party storage and compute platforms such as AWS, Azure and 3rd party data center components.
NetApp Hybrid Cloud Data Services (New)
-
NetApp OnCommand Cloud Manager – Deploy and manage Cloud Volumes ONTAP as well as discover and provision on-premises ONTAP clusters. Available as a SaaS or an on-premises SW.
-
NetApp Cloud Sync – A NetApp SaaS offering that enables easier, automated data migration & synchronisation across NetApp and non NetApp storage platforms across the hybrid cloud. Currently supports Syncing data across AWS (S3, EFS), Azure (Blob), GCP (Storage bucket), IBM (Object storage) and NetApp StorageGRID.
-
NetApp Cloud Secure – A NetApp SaaS security tool that aim to identify malicious data access across all Hybrid Cloud storage solutions. Connects to various storage back ends via a data collector and support NetApp Cloud Volumes, OnTAP, StorageGRID, Microsoft OneDrive, AWS, Google GSuite, HPe Command View. Dropbox, Box, Workplace and Office 365 as end points to be monitored. Not live yet and more details here.
-
NetApp Cloud Tiering – Based on ONTAP Fabric Pools, enables direct tiering of infrequently used data from an ONTAP solution (on premises or on cloud) seamlessly to Azure blob, AWS S3 and IBM Cloud Object Storage. Not a live solution just yet but a technical preview is available.
-
NetApp SaaS Backup – A NetApp SaaS backup solution for backing up Office 365 (Exchange online, SharePoint online, One drive for business, MS Teams and O365 Groups) as well as Salesforce data. Formerly known as NetApp Cloud Control. Can back up data to native storage or to Azure blob or AWS S3. Additional info here.
-
NetApp Cloud backup – Another NetApp SaaS offering, purpose built for backing up NetApp Cloud Volumes (described above)
-
NetApp Kubernetes service – New NetApp SaaS offering to provide enterprise Kubernetes as a service. Built around the NetApp acquisition of Stackpoint. Integrated with other NetApp Data Fabric components (NetApp’s own solutions) as well as public cloud platforms (Azure, AWS and GCP) to enable container orchestration across the board. Integrates with NetApp TRIDENT for persistent storage vlumes.
-
NetApp Cloud Insights – Another NetApp SaaS offering built around ActiveIQ, that provides a single monitoring tool for visibility across the hybrid cloud and Data Fabric components. Uses AI & ML for predictive analytics, proactive failure prevention, dynamic topology mapping and can also be used for resource rightsizing and troubleshooting with infrastructure correlation capabilities.
My thoughts
In the world of Hybrid Cloud, customer data, from VMs to file data can now be stored in various different ways across various data centers, various different Edge locations and various different Public cloud platforms, all underpinned by different set of technologies. This presents an inevitable problem for customers where their data requires transformation each time it gets moved or copied across from one pillar to another (known as platform locking of data). This also means that it is difficult to seamlessly move that data across those platforms during its life time should you want to benefit from every pillar of the Hybrid cloud and different benefits inherent to each. NetApp’s new strategy, powered by providing a common software layer to store, move and manage customer data, seamlessly across all these platforms can resonate well with customers. By continuing to focus on the customer’s data, NetApp are focusing on the most important asset organisations of today, and most definitely the organisations of tomorrow, have. So enabling their customers to avoid un-necessary hurdles to move this asset from one platform to another is only going to go down well with enterprise customers.
This strategy is very similar to that of VMware’s for example (Any App, Any Device, Any Cloud) that aim to also address the same problem, albeit with a more application centric perspective. To their credit, NetApp is the only “Legacy Storage vendor” that has this all-encompassing strategy of having a common data storage layer across the full hybrid cloud spectrum where as most of their competition are either still focused on their data centre solutions with limited or minor integration to cloud through extending backup and DR capabilities at best.
Only time will tell how successful this strategy would be for NetApp, and I suspect most of that success or the failure will rely on the continued execution of this strategy successfully through building additional data and data management services and their positioning to address various Hybrid cloud use cases. But the initial feedback from the customers appears to be positive which is good to see. Being focused on the software innovation has always provided NetApp with an edge over their competitors and continuing on that strategy, especially in an increasingly software defined world is only bound to bring good things in my view.
Slide credit to NetApp & Tech Field Day!
















































{kind=link}