
As a part of the recently concluded Storage Field Day 12 (#SFD12), I had the privilege to sit in front of the engineering & the CxO team of the silicon valley’s newest (and should I say one of hottest) storage start up, Excelero, to find out more about their solution offering on the launch day itself of the company. This post is to summarise what I’ve learnt, and my honest thoughts on what I saw and heard about their solution.
Apologies about the length of the post – Excelero has some really cool tech and I wanted to provide my thoughts in detail, in a proper context! 🙂
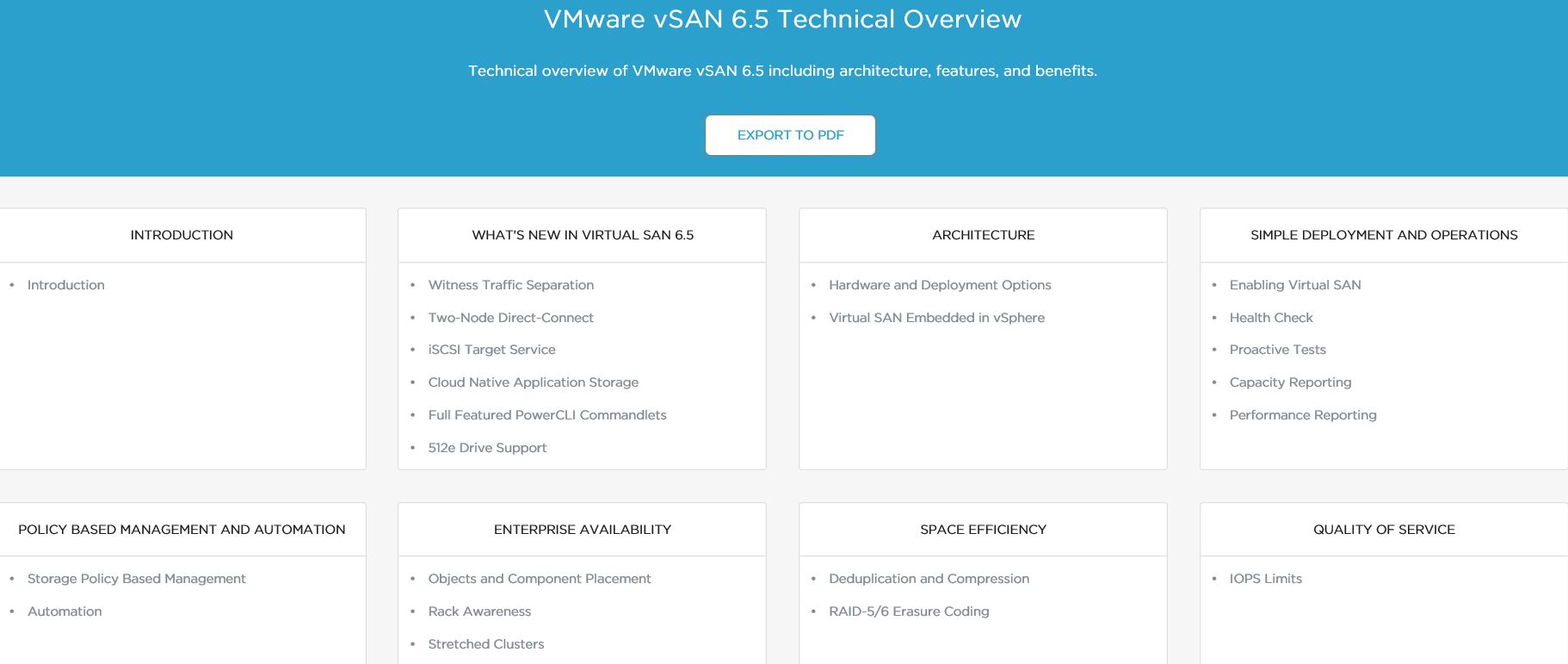
Enterprise Storage Market
So lets start with a bit of context first. If you look at the total storage market as a whole, it has been growing due to the vast and vast amounts of the data being generated from everything we do (consumer as well as enterprise activities). This growth in storage requirements I believe will likely accelerate even faster in the future as we are going to be generating even more data and most of such data are likely going to end up on megascaler’s cloud storage platforms (public cloud). Due to this impact from Public cloud platforms such as AWS, Azure, Google cloud…etc. that suck up most of those storage requirements, the traditional enterprise storage market (where customers typically used to own their own storage) has been very competitive and is perceived to be going through a bit of a downward trend. This has prompted a number of consolidation activities across the storage tech industry and the obvious elephant in the room is the Dell acquisition of EMC while similar other events include HPe’s recent acquisition of Nimble storage and Dell killing off its DSSD array plans etc. So, specially in this supposedly dwindling enterprise storage market (non cloud), the continuous innovation is critical for these enterprise storage vendors in order to compete with Public cloud storage platforms and demand a larger portion of this dwindling, enterprise storage pie. This constant innovation, often software & hardware lead rather than just hardware lead, gives them the ability to provide their customers with faster, larger storage solutions and most importantly a differentiated storage solution offering, together with added data management technologies to meet various 21st century business requirements.
Now, as someone that work in an organisation that partners with almost all of these storage tech companies (legacy and start-ups), I know fairly well that almost every single one of the storage tech vendors are prioritising the use of NVMe flash drives (in its various form factors) as a key focus area for innovation (in most cases, NVMe in itself is their only option without any surrounding innovation which is poor). This was also evident during the #SDF12 event I attended as almost all the storage vendors that presented to us touted NVMe based flashed drives as their key future road map items. Even SNIA – The body for defining standards in the Storage and Networking industry themselves included a number of new NVMe focused standards as being in their immediate and future focus areas. (separate blog post to cover SNIA presentation content from #SDF12 – Stay tuned!).
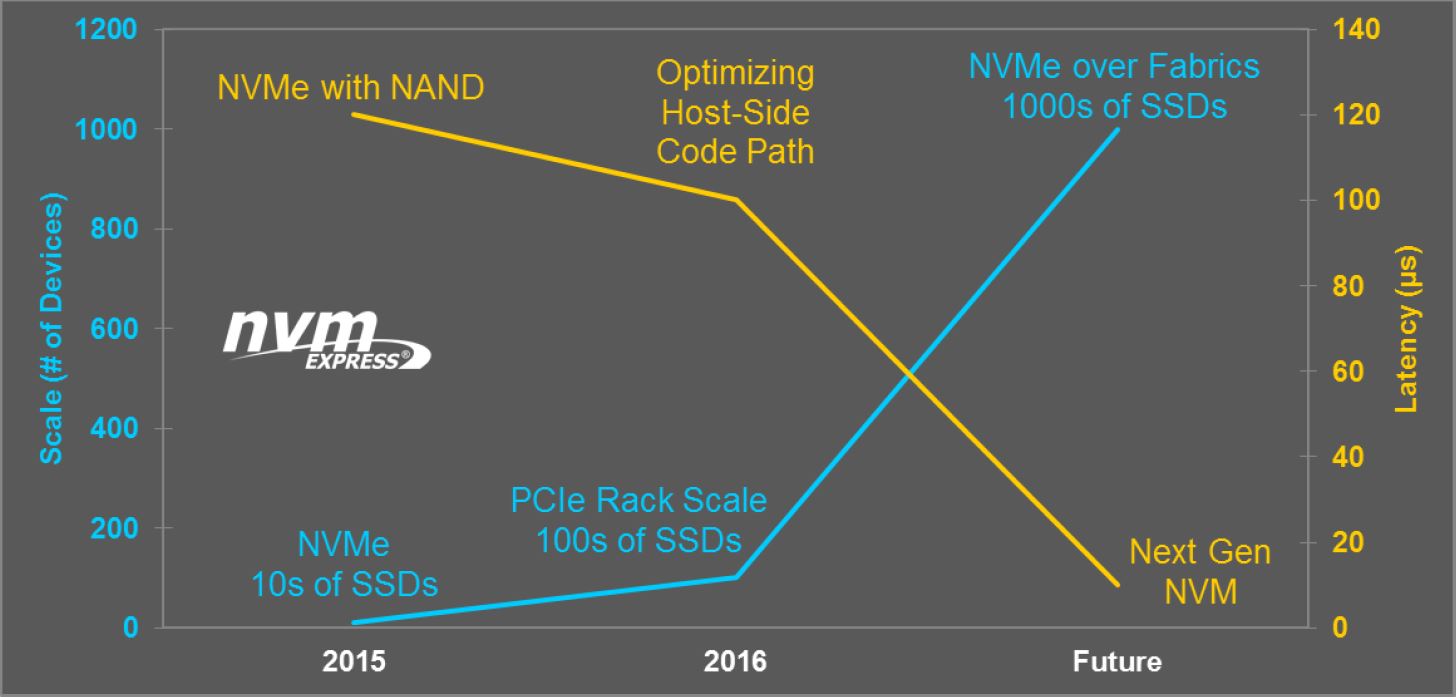
Talking about NVMe in particular, the forecast on the NVMe technology roadmap going in to the future looks somewhat like below (image credit to www.nvmexpress.org) where the future is all focused around NVMe over fabric technologies that can integrate multiple NVMe drives across various different hosts via a high bandwidth NVMe fabric (read “low latency, high bandwidth network”).

-Company Overview-

Excelero is a brand new, Israel tech startup, that was founded in 2014 in Tel Aviv that has a base in Silicon valley, that just came out of stealth on the 8th of March 2017. Despite only just coming out of stealth, as you can see they have some impressive list of high end customers on the list already.
Their offering is primarily a SDS solution with some real innovation in the form of an efficient (& patented) software stack, engineered to exploit latest development in the storage hardware technologies such as NVMe drives, NVMe over Fabric (NVMesh) and RDMA technology all working in harmony to boost NVMesh performance, unlike any other storage vendor that I know of (At this point in time). They have built a patented software stack focused around RDDA (Remote Direct Data Access which is similar to RDMA in how it operates – more details below) which by passes CPU (& memory to a level) on the storage controllers / nodes / servers when it comes to storage IO processing, such that it requires zero CPU power on the storage node to serve IO. If you are a storage person, you’d know the biggest problem is / has been in the storage industry for scaling performance up is the CPU power on the storage nodes / controllers, especially when you use NAND technologies such as SSD and this is why if you look at every All Flash Array, you’ll see a ton of CPU cores operating at a very high frequency in every controller node. Excelero is conveniently getting around this issue by de-coupling storage management & data and most importantly, using RDDA technology to bypass storage server CPU for disk IO (which is now offloaded to a dedicated RDMA capable network card (RoCE / RNIC) such as Mellanox Connectrix-3/4/5 card).
In a nutshell (and this is for the sales people that reads this) – Excelero is a scale out, innovative, Software Defined Storage solution that is unlike any other in the market right now. They use next generation storage & networking hardware technologies to provide a low cost, extremely low latency, extremely high bandwidth storage solution for specific enterprise use cases that demands such a solutions. Excelero claims that they can produce 100 million IOPS along with some obscene bandwidth throughputs with little to no CPU capacity on the server side (storage nodes) and I believe them, especially after having seen a scaled down demo in action. I would say they are probably one of the best if not the best solution of its kind available in the market right now and that is my honest view. Please read on the understand why!
-Use Cases-
Typical use cases Excelero initially aims to address are any enterprise business requirements looking for a high bandwidth, ultra low latency, block protocol storage solution. Some of the typical examples are as follows.



Technical Overview
Advanced warning:
- If you are a SALES GUY, FORGET THIS SECTION!. I’m certain it aint gonna work for you! Honestly, don’t waste your time. Just skip this section and read the next section 🙂
- If you are a techie however, do carry on.
It is important first of all to understand some key concepts used within the Excelero solution and their architectural overview.
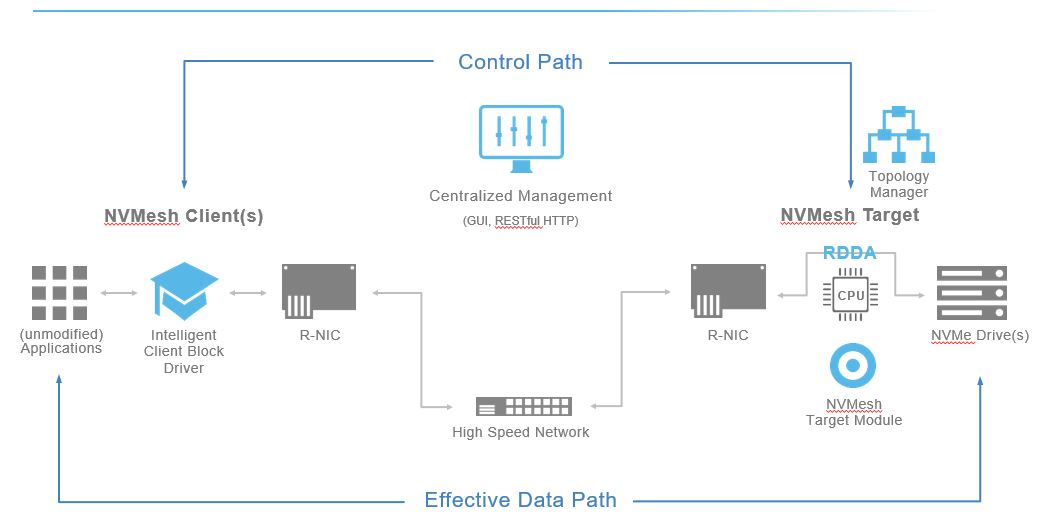
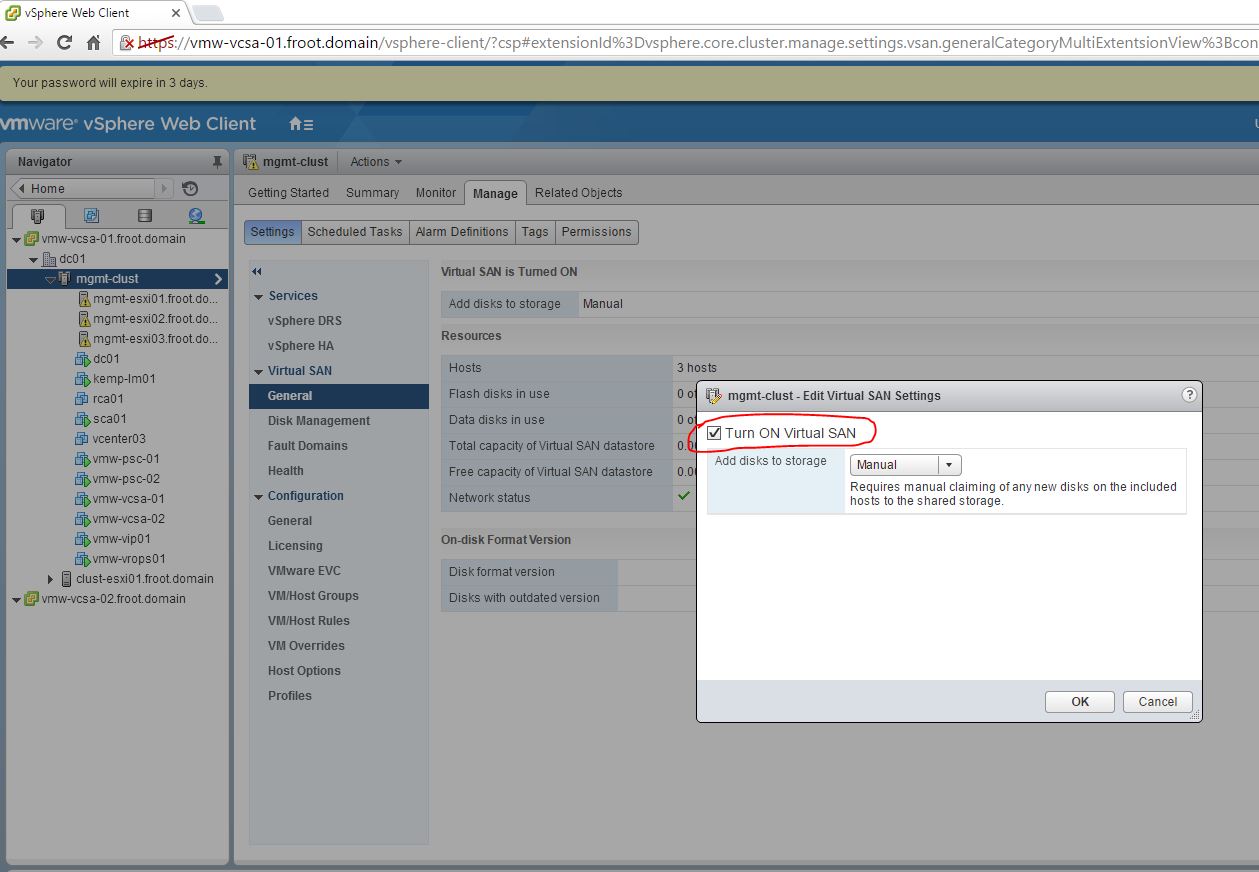
-NVMesh Architecture-
The NVMesh server SAN Architecture that Excelero has built is a key part of the Excelero software stack & given below is a high level overview.


NVMesh is the technology using which Excelero aggregates various remote NVMe drives in to a single pool of drives that are accessible by all participating storage nodes over the NVMe fabric network, but most importantly as local drives (with local drive characteristics such as latency)
- NVMesh design goals:
- Performance, Scalability, Integration, Flexibility, Efficiency, Ease of use
- Components involved
- Control path
- Centralised management for provisioning, management & all control activities. (All intelligence reside at this layer)
- Runs as a Node.js application on top of MongoDB
- Pools drives, provisions volumes and monitor
- Transforms drives from raw storage into a pool
- Also includes topology manager which
- Runs on all the nodes as a distributed service
- Implements the cluster management and HA
- Performs volume lifecycle management
- Uses Multi-RAFT protocols avoid split brain and RAIN data protection across a large node cluster
- Communicates with the target software that runs on the storage nodes
- Rest-full API for integration with automation and external orchestration platforms such as Mesos (Kubernetes support is on the road map)
- Docker support with a persistent storage plugin available
- Data path
- Kernel module that manages drives and act as a storage server for clients
- Provide true convergence which removes target module from the data path (CPU) such that storage nodes can run applications and other data services on the server nodes without CPU conflict / Impact (node that this is a new definition to hyper-converged compared to other HCI vendors such as VMware / Nutanix …etc.)
- Point to point communication with other storage nodes, management & clients
- NVMesh client
- Intelligent client block driver (Linux) where client side storage services are implemented
- Kernel module that presents logical volumes via the above block driver API
- No need for iSCSI or FC as the Excelero solution is not using SCSI protocol for communication
- NVMesh target
- Hardware components
- Standard X86 servers with NVMe drives (more details on HW below) & RNIC cards
- Next generation switches
- Software components (Excelero Intellectual Property)
Note that the current version of NVMesh (1.1) is supported on Linux only and lacks any specific data services such as de-duplication & compression etc but these services are included in the roadmap. Based on what was disclosed to us, some these future improvements include QoS capabilities, Additional drive media support, additional Hardware architecture support, Non-Linux OS support, Additional deployment methods, reduced power configurations as well as integration with Software Defined Networking solutions which sounds very promising as a total solution as was very good to hear.

-RDDA (Remote Direct Data Access)-
RDDA is the patented secret sauce that Excelero has developed which is the other most important part of their solution stack. It works hand in hand with the NVMesh software stack (described above) and its primary purpose is to avoid the use of CPU on the storage nodes, when processing client IO.
They key points to note about the RDDA technology is
- Developed a while ago by Excelero to fill a gap that was in the market. (A new replacement for this is coming soon)
- No CPU utilisation on the target side – This is achieved through the RDDA technology which bypasses the target side CPU
- RDDA only works with NVMe & is highly optimised for NVMe & remote NVMe access (so if you use non NVMe drives, which is also possible, there are no RDDA capabilities)
- However if used in converged mode (centralised storage), RDDA is not used so target side CPU will have an impact
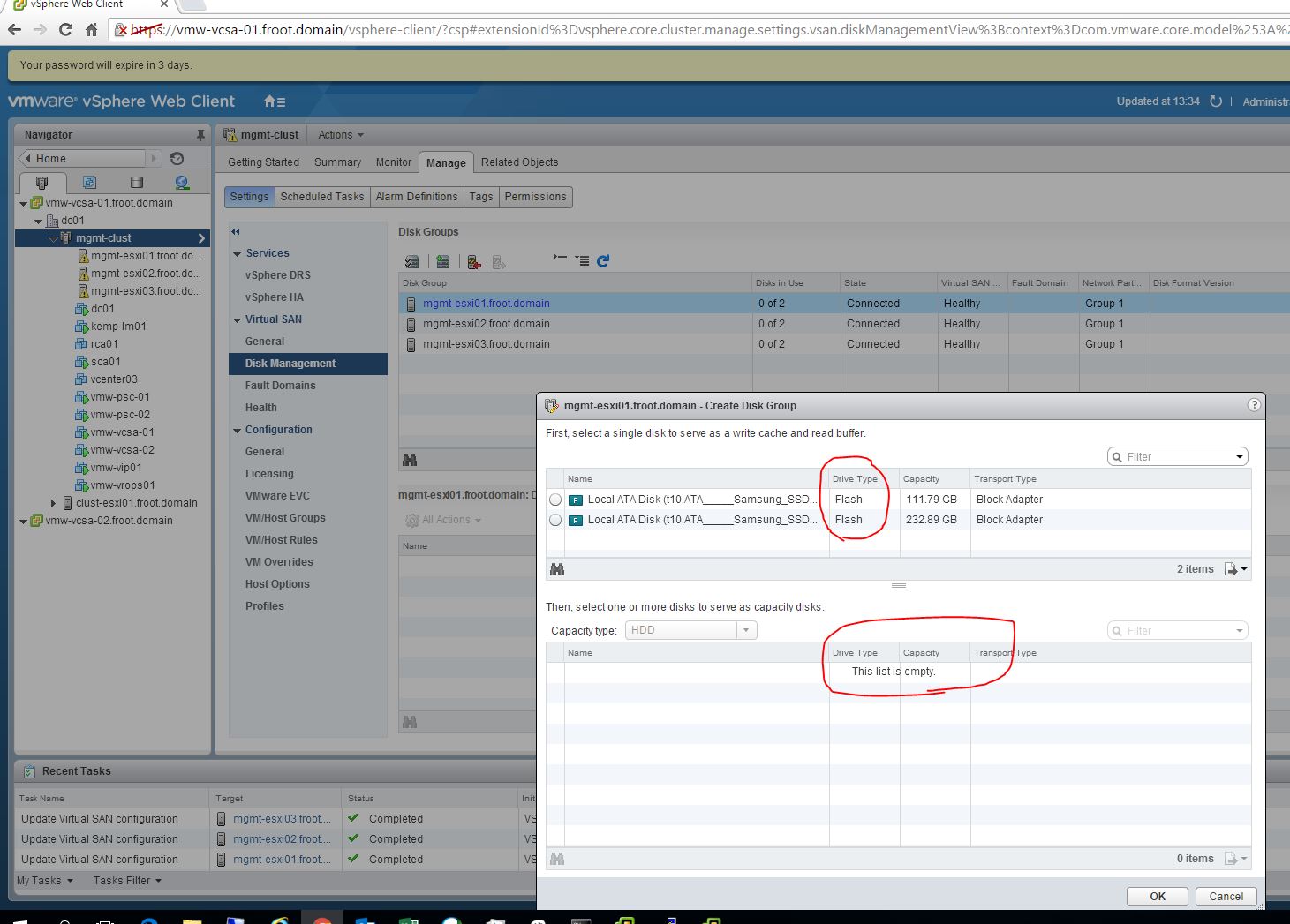
Now I’m not an expert of how a typical NVMe read / write would occur and all the typical sub-protocol level steps that are involved. But from what I gathered based on their architect’s description, given below are the high level steps involved in Excelero’s RDDA technology when it comes to local and remote NVMe writes and reads. I’ve included this in order to explain at a high level how this technology differs to others and why the CPU is no longer necessary on the target side.
Pre-requisite knowledge: If you are unfamiliar with certain NVMe operations & techniques such as submission queue, completion queue, doorbell..etc which are typically used in a NVMe I/O operation, refer to this article for a basic understanding of it first before reading the below in order to make better sense. The below image is from that article

Now that you supposedly understand the NVMe commend process, lets have a look at Excelero’s high level implementation of RDDA (based on my understanding – Actual process may slightly differ or have many more steps / validations…etc.)
- Each client side read or a write will always result in a single RDMA write that is sent from the client side directly in to the destination storage node. There are 3 pieces of this NVMe write that occur on the storage node.
- Local write (if to a local NVMe disk) or a remote write (if reading or writing to a remote NVMe drive) to the NVMe drive’s submission queue. This include any data to be written if that’s a write operation where write data is put in to the local or remote memory and is referenced within this write in the submission queue.
- Also writes in to the RNIC’s queue (memory) a message (memory buffer called a “Bounce buffer” which is made to point to the completion queue of the NVMe drive) to be sent back to the client (imagine a sort of a pre-paid envelop). This is effectively a pre-prepared message to be sent back to client (to be used if it’s a read request)
- Ring the doorbell on the NVMe drive (to start executing) after which the NVMe drive on the storage node will start acting to execute the IO operation. (Note that so far, there were no CPU operations on the storage node as no storage side SW has been used).
- If it’s a read op, it will then fill the bounce buffer that was pre-prepared in the step 2 above with the data that is read from the NVMe disk.
- If it’s a write op, it will write the data that was put in to memory (above) to the disk.
- Once the above NVMe operation is complete, it will generate 2 things
- Small completion (less important part)
- Most important part is that it then generate a MSI-X interrupt. Typically speaking, MSI-X interrupts are targeted at the CPU which is why during IO cycles, the CPU utilisation on the storage controllers go up. Unlike in a typical MSI-X interrupt’s case, with Excelero RDDA, the MSI-X interrupt is pre-programmed to not go to the CPU but instead, go ring the doorbell of the NVMe NIC. Upon this doorbell, the NVMe NIC will then send the pre-prepared Bounce buffer (step 2 above) which was pointing at the completion queue of the NVMe drive read data if that was a read operation, or if that was a write op, it would send the completion queue details along with some other data back to the client via the NVMe fabric, involving “ZERO” CPU on the storage node. This bit is the Excelero’s patented technology that allows them to NOT use any CPU on the storage server side during any IO operation no matter how big the IOPS / bandwidth is
You’ll see from this high level operation flow that during the whole IO process, no server side CPU was ever required & all the IO processing were carried our by the RNIC’s and the NVMe drives, and the traffic transported across the NVMe fabric (network). Note however that on client side, CPU is used as normal (similar to any other client accessing storage). Also note that there is no concept of caching to memory when it comes to write IO (no nvram) and therefore the acknowledgement is only sent back to the client once the data is written to the NVMe drive.
The current RNICs used within the Excelero solution are Mellanox (to be specific, Mellanox Connectrix-3/4/5) but they’ve mentioned that it could also work on Q-Logic RNIC cards too. Excelero also indicated that they are already working with another large networking vendors for additional RNIC card support, though didn’t mention exactly who that is (Cisco or Broadcom??)
-RAIN Architecture-
Excelero uses a concept of RAIN (similar to RAID) when it comes to provisioning volumes and providing high availability. Key details are as follows.
- A logical volume is a RAIN data protected volume which consist of one or more partial drives. (i.e. high performance volume may include a number of drives but only a part of each drive’s capacities may be used)
- The key differentiator here is that as opposed to RAID which is across local disks, RAIN is across disks from multiple host (similar to network RAID)
- Current version of the solution support RAIN10 (imagine RAID 10 over the NW but this time over NVMe fabric)
- Erasure coding would be available soon
-Deployment Architecture-
Excelero solution is supported as both Local Storage in Application server mode (similar to Hyper-Converged but without a hypervisor) as well as converged (centralised storage) mode and each method will have certain limitations (such as RDDA not being applicable in a converged deployment). You can supposedly deploy them in mixed mode too though I don’t quite remember who that works.
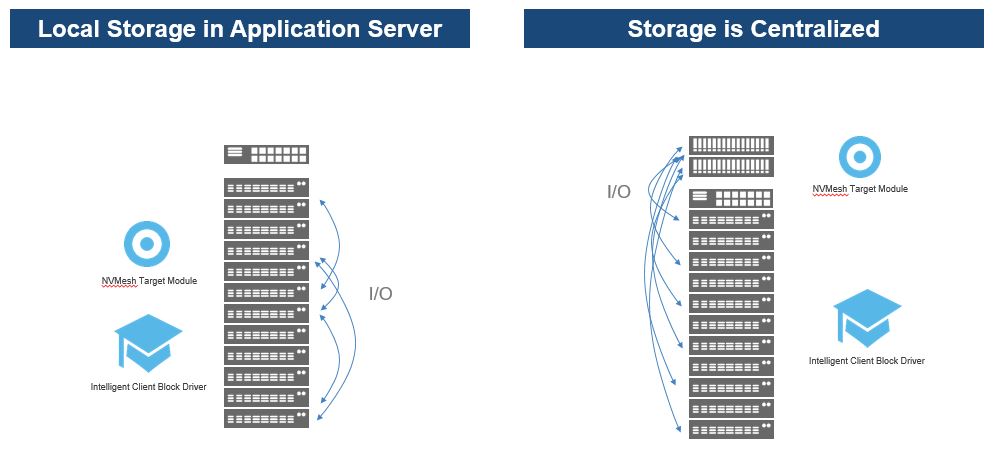
Performance
Excelero boasts some obscene performance levels to produce 100 million IOPS with little to no CPU capacity on the storage nodes which totally seems believable. It is important to understand that Excelero doesn’t necessarily promise to deliver more IO / bandwidth than a NVMe disk manufacturer claims possible from a raw NVMe disk, but they ensure that the maximum possible capability can be extracted from a NVMe drive with NAND storage when used with their solution. In order to do that, Excelero NVMesh & RDDA technologies combine to present remote NVMe drives as local drives which makes a significant difference to the latency that is possible with no CPU penalty on server side. No other storage vendor can provide such capability as far as I know (Perhaps, except for HPe’s prototype “Machine project” that is supposedly looking at the use of Photonics to reduce the distance between processors and persistent local and remote memory which is used as storage. However this is not a shipping product and its doubtful whether it would ever ship, and if does, its likely going to cost an obscenely high amount, compared to low cost option available with Excelero)
In order to see whats possible, we were treated to a live demo of their platform running on a bunch of Supermicro commodity server hardware with lower scale Intel Xeon CPU’s and a mix of Intel and Samsung NVMe drives interlinked with Mellanox ConnectX-5 100Gbs Ethernet RoCE adaptors and a Dell Z9100-ON network switch.
Its fair to say, the demo results blew our socks off!!! And we did have some storage industry stalwarts in our delegate panel at #SFD12 who’s been there in the storage industry since its enterprise inception and every one of those guys (and myself) were grinning from the left year to the right, when watching this demo and the stats that came out (that’s a “GOOD” thing in case it wasn’t clear :-)).
When 4 x Intel 400GB NVMe drives from 4 different hosts were used in a single storage pool and performed a random read operation with 4K IO’s, the stats we saw were around 4.9 million IOPS @ 25GB/s bandwidth and less than or around 200µs of latency (consistently) – This was somewhat previously unseen!

When the write test was shown (on the same disk pool across 4 servers) with 4K writes, the results were around 2.4 million IOPS @ < 200µs latency.

We were also shown the CPU stats during the IO operations where the CPU utilisation on each storage node was hovering around 0.84% throughout the entire demo to prove the RDDA technology clearly bypasses the server side CPU which was super impressive. These IOPS & latency figures were more than good numbers and while I couldn’t verify this, Excelero team mentioned to us that the server configs used for this demo only cost them $13,000 each which, if true, is a massive cost saving that is potentially available for all future Excelero customers here.
With RDDA, IO performance is now offloaded from the storage node CPU to the RNIC & the Ethernet fabric and while their saturation points are much higher than in a traditional architecture that relies on host CPU, the capabilities of the fabric the RNIC cards are now likely going to be the performance bottleneck in the future so if someone’s architecting a solution using Excelero, it would be pretty important to make the appropriate design choices on the fabric and the RNIC cards to make the solution future proof.
Solution Licensing & Costs
We didn’t discuss much around the costs and we were not privy to list pricing, however its very likely that that the licensing & costs would be,
- Flexible pricing, and likely going to cost similar to that of a matching All Flash Array but Excelero would provide around 20-30% more performance
- Can be licensed per NVMe drive or per server (Not penalised for capacity of the drive which is good)
- Hyper-Converged: Storage nodes where the storage is brought local to application servers (no hypervisor involved)
- Centralized (Converged): Separate price for storage nodes and client nodes
Customer Case Studies
Despite being a fresh start-up, they have some impressive customers already on board such as NASA, PayPal, Dell, Micron, Broadcom, HPe, Intel and most importantly they are an integral part of the LinkedIn’s Open19 project (New open standard for servers, storage & networking – I will produce a separate article on Open 19 in the future and much line the OCP project, its going to help define the datacenter of tomorrow).
In the case of the NASA’s deployment of Excelero, we were made to understand that the solution is capable of doing around 140GB/s write throughput across 128 servers which is astonishing.
Some popular customer case studies that are publicly referenceble are as follows


My Thoughts
Put simply, I like their solution offering….! A lot…!! – No wait… that’s an understatement. I absolutely love their solution offering and the level of innovation they seem to have put in to it. For certain workloads that are pure performance centric and cares less about advanced data services, I think Excelero solution would be the one to beat, at least in the short term in the industry.
As of right now, if you look at all hardware and software defined storage solutions that are generally available to purchase in the market, in my view, Excelero has a unique offering when it comes to its target market. Some of those uniqueness comes from the below points
- They have the only virtual SAN (SDS) solution that will harness shared NVMe (NVMe over fabric) in the market today
- Unified NVMe which enables sharing storage across a network but still accessed at local speeds and latencies
- No CPU impact for storage IO on the storage node
- Flexible architecture that provide hyper-converged as well as converged (disaggregated) architectures
There are a ton of SDS solutions out there in the market, some from the legacy storage vendors such as Cisco, HPe, EMC as well as dedicated SDS vendor start-ups (that are no longer start-ups such as Nutanix, VMware vSAN, HedVig…etc.) and typically most of these solutions will look at using industry standard disk drives with industry standard server hardware (X86) plus, their own storage software stack on top, typically as a dedicated (read “centralised”) storage node or as a hyper-converged offering (read “de-centralised”). Excelero is no different from an architectural perspective to most of these SDS vendors. However due to its additional unique capabilities such as RDDA & NVMesh, their SDS solution stack is likely going to be very attractive for most high end, ultra low latency storage requirements where no other SDS or a even a purpose build All Flash Array will no longer be able to compete anymore. This is precisely Excelero’s initial target market and I would presume they would do very well within that segment, provided that they get their marketing message right.
However given the current lack of advanced data services, it is unlikely that they’d replace more mature, HCI or SDS offerings that are much richer in advanced data services such as VMware VSAN, Nutanix as well as All Flash Array offerings from the likes of NetApp (All Flash FAS or SolidFire), HPe 3Par All Flash, EMC XtremIO, when it comes to more common purpose mixed use cases, such as virtualisation platforms or VDI. Having said that, you can argue that Excelero’s offering is a version 1 product right now and future versions will add these missing advanced data services which will make it equally competitive or even better. Due to the lack of CPU dependency on storage IO processing, Excelero can afford to overload it’s storage nodes with so many advanced data services, all run inline and always on without any impact on any IO performance which is a big headache other All Flash Storage Array or SDS vendors cannot avoid. So in theory, Excelero’s storage platform in time could be even superior than it is today.
At present, Excelero has 2 Go To Market (GTM) routes.
- The obvious one is direct to customers in order to address their key use case (ultra low latency, high IOPS / Throughput use cases)
- The other route to market is working with OEM manufacturers
While Excelero will continue to enhance their core offering available under 1st GTM route above, I can see many other OEM vendors such as the legacy storage vendors wanting to license Excelero’s patented technology such as RDDA in order to be used in their own storage systems and this could well be quite popular revenue stream for Excelero. In my view, having an awesome technology doesn’t necessarily ensure the survival of a tech start up and this 2nd GTM route may well be the obvious starting point for them, though then they are potentially limiting the technical advantage they have on the GTM 1.
Either way, they have an awesome, credible and based on current customers, a popular storage technology and I sincerely hope the business leaders within the company will make the strategically best decisions on how to monetize this exciting technology they have. Given the lack of similar technology from other vendors at the moment, Excelero may have a slight advantage but the competition is unlikely to sit and wait as they too will likely work on similar but different architectures. Intel have already hinted to us during our session at #SFD12 that there may well be a newer replacement to NAND based drives coming out soon from Intel and pretty soon, NVMesh & RDDA could well be a thing of the past before you know it so I hope my friends in Excelero act fast.
Finally, a group photo of the Excelero team that presented to us along with the #SFD12 delegates panel 🙂

Additional Reading
If you are keen to explorer further in to Excelero and their solutions, the obvious place to start is their web site but if you would like to watch the recording of the presentation they gave to #SFD12 team, its available here.
If you have any questions or thoughts, please feel free to submit a comment below
Slide credit goes to Excelero and Tech Field Day
Thanks
Chan
#SDF12 #Excelero























{kind=link}