
There are some exciting technology developments taking place in the storage industry, some behind closed doors but some that are also publicly announced and already commercially available that most of you may already have come across. Some of these are organic developments to build on existing technologies but some are inspired by megascalers like AWS, Azure, GCP and various other cloud platforms. I’ve been lucky enough to be briefed on some of these when I was at SFD12 last year I the Silicon Valley, by SNIA – The Storage and Networking Industry Association that I’ve previously blogged about here.
This time around, I was part of the Storage Filed Day (SFD15) delegate panel that got a chance to visit NetApp at their HQ at Sunnyvale, CA to find out more about some of exciting new product offerings that are in NetApp’s roadmap, either in the works or starting to just come out, incorporating some of these new storage technologies. This post aim to provide a summary of what I learnt there and my respective thoughts.
Introduction

It is no secret that Flash media has changed the dynamics of the storage market over the last decade due to their inherent performance characteristics. While the earliest incarnations of flash media were prohibitively expensive to be used in mass quantities, the invention of SSDs commoditised the use of flash media across the entire storage industry. For example, most tier 1 workloads in the enterprises today are held on a SSD backed storage system where SSD disk drives form the whole or a key part of the storage media stack.
When you look at some of the key storage solutions in use today, there are 2 key, existing flash technologies that stand out, DRAM & SSD. DRAM is the fastest possible flash storage media that is most easily accessible by the data processing compute subsystem while SSD’s fall in to next best place when it comes to speed of access and the level of performance (IOPS & bandwidth). As such, most enterprise storage solutions in the world, be that the ones aimed at the customer data centers or on the megascaler’s cloud platforms utilise one or both of these flash media types to either accelerate (caching) or simply store tier 1 data sets.
It is important to note that, while the SSD’s benefitted from the overall higher performance and lower latency compared to mechanical drives due to the internal architecture of the SSD disks themselves (flash storage cells that don’t require spinning magnetic media), both the SSD drives and classic mechanical (spinning) drives are typically attached & accessed by the compute subsystem via the same SATA or the SaS interface subsystem with the same interface speed & latency. Often the internal performance of an SSD was not fully realised to its maximum potential, especially in an aggregated scenario like that of an enterprise storage array, due to these interface controller access speed and latency limitations, as illustrated in the diagram below.
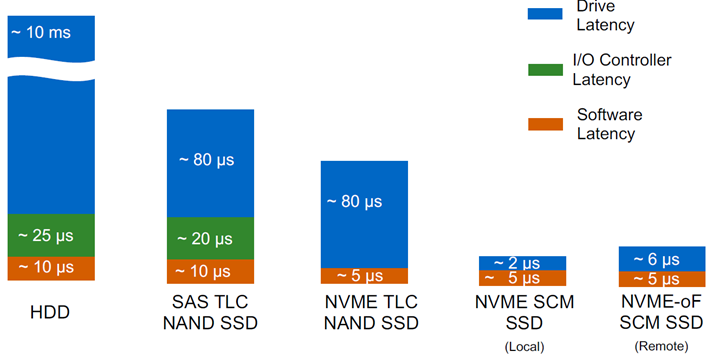
One of the more recent technology developments in the storage and compute industry, namely “Non-Volatile Memory Express” (NVMe) aims to address these SAS & SATA interface driven performance and the latency limitations through the introduction of new, high performance host controller interface that has been engineered from the ground up to be able to fully utilise flash storage drives. This new NVMe storage architecture is designed to be future proof and would be compatible with various future disk drive technologies that are NAND based as well as non-NAND based storage media.
NVMe SSD drives connected via these NVMe interfaces will not only outperform traditional SSD drives attached via SAS or SATA, but most importantly will enable higher future capabilities such as being able to utilise Remote Direct Memory Address (RDMA) for super high storage performance extending the storage subsystem over a fabric of interconnected storage and compute nodes. A good introduction to the NVMe technology and its benefits over SAS / SATA interfaces can be viewed here.
Another much talked about development on the same front is the subject of the Storage Class Memory (SCM) – Also known as Persistent Memory (PMEM). SCM is an organic successor to the NAND technology based SSD drives that we see in mainstream use in flash accelerated as well as all flash storage arrays today.
At a theoretical level, SCM can come in 2 main types as shown in the above diagram (from a really great IBM research paper published in 2013).

-
M-Type SCM (Synchronous) = Incorporate non-volatile memory based storage in to the memory access subsystem (DDR) rather than SCSI block based storage subsystem through PCIe, achieving DRAM like throughput and latency benefits for persistent storage. Typically take the form of NVDIMM (that is attached to the memory BUS, similar to traditional DRAM) which is the fastest and best performant thing, next to DRAM itself. Uses memory card slots and appear to the system to use as a caching layer or as pooled memory (extended DRAM space) depending on the NVDIMM type (NVDIMMs come in 3 types, NVDIMM-N, NVDIMM-F and NVDIMM-P. A good explanation available here).
- S-Type SCM (Asynchronous) = Incorporate non-volatile memory based storage but attached via the PCIe connector to the storage subsystem. While this is theoretically slower than the above, it’s still significantly faster than NAND based SSD drives that are in common use today, including those attached via NVMe host controller interface. Intel and Samsung both have already launched S-type SCM drives, Intel with their 3D XPoint architecture and Samsung with Z-SSD respectively but current drive models available are aimed more at consumer / workstation rather than server workloads. Server based implementations of similar SCM drives will likely arrive around 2019. (Along with supported server based software included within operating systems such as Hypervisors – vSphere 7 anyone?)
The idea of the SCM is to address the latency and performance gap that exist in every computer system when it comes to memory and storage since the advent of X86 computing. Typically, access latency for DRAM is around 60ns, and the next best option today, NVMe SSD drives will have a typical latency of around 20-200us and the SCM will fit in between these 2, at a typical latency between 60ns-20uS, depending on the type of the SCM, with a significantly high bandwidth that is incomparable to SSD drives. It is important to note however that most ordinary workloads do not need this type of super latency sensitive, extremely high bandwidth storage performance, the next generation data technologies involving Artificial Intelligence techniques such as machine learning, real-time analytics that relies on processing extremely large swathes of data at super quick time, would absolutely benefit, and in most instance, necessitate the need for these next gen storage technologies to be fully effective.
NetApp’s NVMe & SCM vision
NetApp was one of the first classic storage vendors who incorporate flash in to their storage systems, in an efficient manner to accelerate the workloads that is typically stored on spinning disks. This started with the concept of NVRAM that was included in their flagship FAS storage solutions as an acceleration layer. Then came the flash cache (PAM cards) which were flash media attached via the PCIe subsystem to act as a cashing layer for reads which was also popular. Since the advent of all flash storage arrays, NetApp went another step by introducing all flash storage in to their portfolio through the likes of All Flash FAS platform that was engineered and tuned for all flash media as well as the EF series.
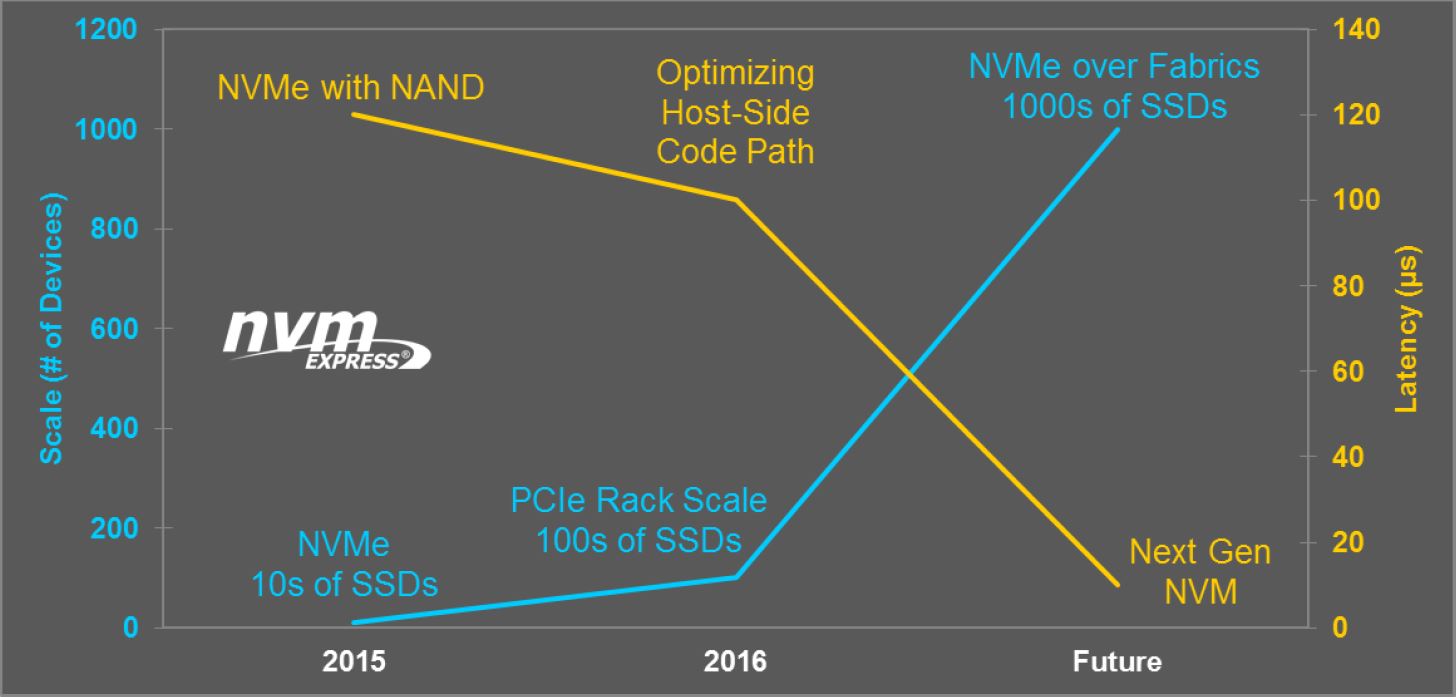
NetApp innovation and constant improvement process hasn’t stopped there. During SFD15 event, we were treated to the next step of this technology evolution by NetApp when they discussed how they plan to incorporate the above mentioned NVMe and SCM storage technologies in to their storage portfolio, in order to provide next gen storage capabilities to serve next gen use cases such as AI, big data and real-time analytics. Given below is a holistic roadmap plan of where NetApp see NVMe and SCM technologies fitting in to their roadmap, based on the characteristics, benefits and costs of each technology.

The planned use of NVMe is clearly in 2 different points of the host->storage array communication path.
- NVMe SSD drives : NVMe SSD drives in a storage array, attached via NVMe host controller interface in order to be able to fully utilise the latency and throughput potential of the SSD drives themselves by the storage processor (in the controllers). This will provide additional performance characteristics to the existing arrays.
-
NVMe-OF : NVMe over fabric which is attached to the storage consumer nodes (Servers) via a ultra-low latency NVMe fabric. NVMe-OF enable the use of RDMA capabilities to reduce the distance between the IO generator and the IO processor thereby significantly reducing the latency. NVMe-OF therefore is widely touted to be the next big thing in storage industry and a number of specialists start-ups like Excelero have already come out to market with specialist solutions and you can find out more about it in my blog here. An example of the NVMe-OF storage solution available from NetApp is the new NetApp EF570 all flash array. This product is already shipping and more details can be found here or here. This platform offers some phenomenal performance numbers at ultra-low latency, built around their trusted, mature, feature rich, yet simple EF storage platform which is also a bonus.
-

The planned (or experimented) use of SCM is in 2 specific areas of the storage stack, driven primarily by the costs of the media vs the need for acceleration.
-
Storage controller side caching: NetApp mentioned that some of the experiments they are working on with prototype solutions already built are looking at using SCM media on the storage controllers as a another tier to accelerate performance, in the same way PAM cards or Flash cache was used on the older FAS system. This a relatively straight forward upgrade and would be specially effective in an all flash FAS solution with SSD drives in the back end where a traditional flash cache card based on NAND cells would be less effective.
-

-
Server (IO generator) side caching: This use case looks at using the SCM media on the host compute systems that generates the IO to act as a local cache, but most importantly, used in conjunction with the storage controllers rather than in isolation, performing tiering and snapshots from the host cache to a backend storage system like an All Flash FAS.
-

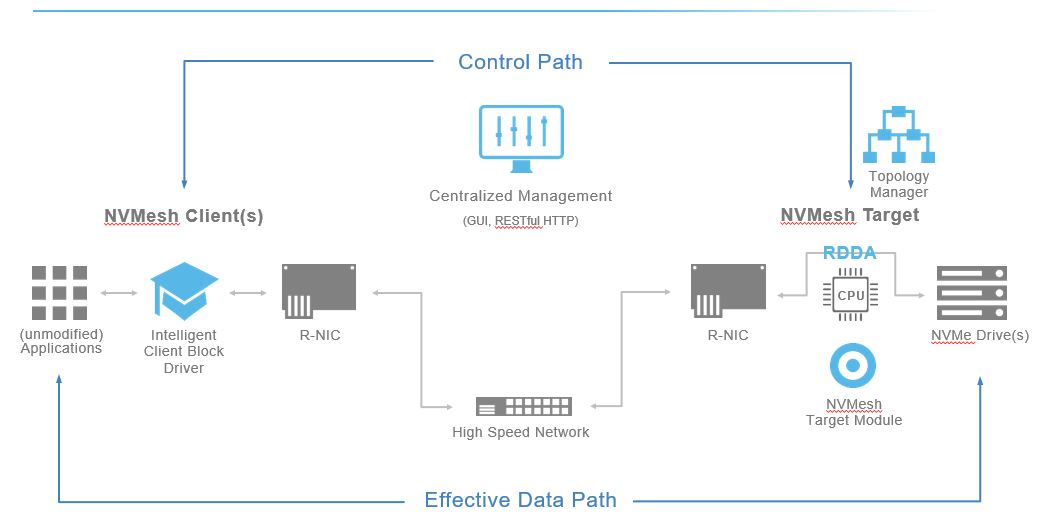
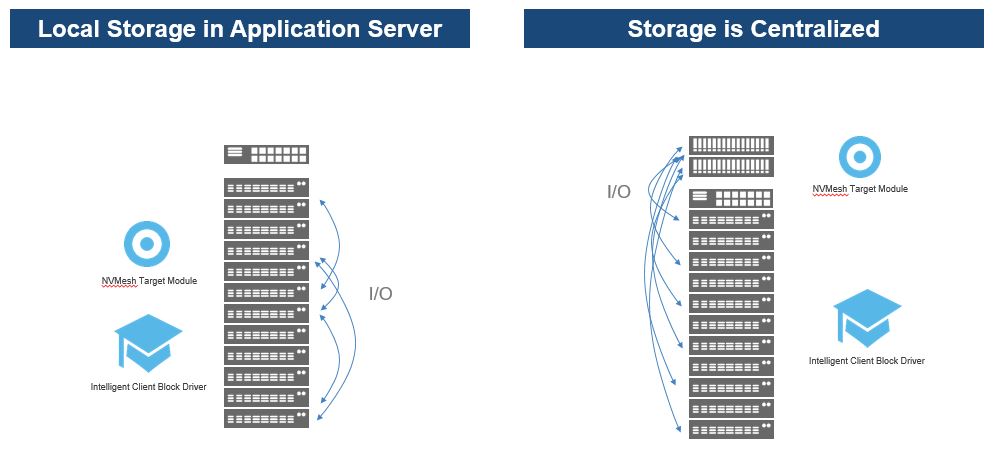
- NetApp are experimenting on this front primarily using their recent acquisition of Plexistor and their proprietary software that performs the function of combining DRAM and SCM as a single address space that is byte addressable (via memory semantics which is much faster than scsi / NVMe addressable storage) and presenting that to the applications as a cache while also presenting the backend NetApp storage array such as an All Flash FAS as a persistent storage tier. The applications achieve significantly lower latency and ultra-high throughput this way through caching the hot data using the Plexistor file system which incidentally bypasses the complex Linux IO stack (Comparison below). The Plexistor tech is supposed to provide enterprise grade feature as a part of the same software stack though the specifics of what those enterprise grade features meant were lacking (Guessing the typical availability and management capabilities as natively available within OnTAP?)

Based on some of the initial performance benchmarks, the effect of this is significant, as can be seen below when compared to a normal

My thoughts
As an IT strategist and an Architect at heart with a specific interest in storage who can see super data (read “extremely large quantities of data”) processing becoming a common use case soon across most industries due to the introduction of big data, real-time analytics and the accompanying Machine Learning tech, I can see value in this strategy from NetApp. Most importantly, they are looking at using these advanced technologies in harmony with some the proven, tried and tested data management platforms they already have in the likes of OnTAP software could be a big bonus. The acquisition of Plexistor was a good move for NetApp and integrating their tech and having a shipping product would be super awesome if and when that happens but I would dare say the use cases would be somewhat limited prohibitive initially given the Linux dependency. Others are taking note and the HCI vendor Nutanix’s acquisition of PernixData kind of hints Nutanix also having a similar strategy to that of Plexistor and NetApp.
While the organic growth of current product portfolio with capabilities through incorporating new tech such as NVMe is fairly straight forward and help NetApp stay relevant, it remains to be seen however how well acquisition driven integration such as that of Plexistor with SCM technologies to the NetApp platform would pan out to become a shipping product. NetApp has historically had issues around the efficiency of this integration process which in the past has known to be slow but this time around, under the new CEO George Kurian who brought in a more agile software development methodology and therefore, a more frequent feature & update release cycle, things may well be different this time around. The evidence seen during SFD15 pretty much suggest the same to me which is great.
Slide credit to NetApp!
Thanks
Chan














































{kind=link}